










Cracking the Machine Learning Code: Technicality or Innovation?
(0 Bewertungen)15
Buch (kartoniert)
Buch (kartoniert)
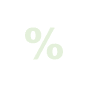
170,99 €inkl. Mwst.
Zustellung: Fr, 30.05. - Mo, 02.06.
Versand in 2 Tagen
VersandkostenfreiBestellen & in Filiale abholen:
Employing off-the-shelf machine learning models is not an innovation. The journey through technicalities and innovation in the machine learning field is ongoing, and we hope this book serves as a compass, guiding the readers through the evolving landscape of artificial intelligence. It typically includes model selection, parameter tuning and optimization, use of pre-trained models and transfer learning, right use of limited data, model interpretability and explainability, feature engineering and autoML robustness and security, and computational cost efficiency and scalability. Innovation in building machine learning models involves a continuous cycle of exploration, experimentation, and improvement, with a focus on pushing the boundaries of what is achievable while considering ethical implications and real-world applicability. The book is aimed at providing a clear guidance that one should not be limited to building pre-trained models to solve problems using the off-the-self basic building blocks. With primarily three different data types: numerical, textual, and image data, we offer practical applications such as predictive analysis for finance and housing, text mining from media/news, and abnormality screening for medical imaging informatics. To facilitate comprehension and reproducibility, authors offer GitHub source code encompassing fundamental components and advanced machine learning tools.
Inhaltsverzeichnis
Chapter 1. Introduction. - Chapter 2. Data modalities and preprocessing. - Chapter 3. Basic building blocks: From shallow to deep. - Chapter 4. Experimental Setup. - Chapter 5: Case study: from numbers to images. - Chapter 6: Extension: Multimodal learning representation. - Chapter 7. Where is the innovation? .
Produktdetails
Erscheinungsdatum
10. Mai 2025
Sprache
englisch
Seitenanzahl
148
Reihe
Studies in Computational Intelligence
Autor/Autorin
KC Santosh, Rodrigue Rizk, Siddhi K. Bajracharya
Verlag/Hersteller
Produktart
kartoniert
Gewicht
236 g
Größe (L/B/H)
235/155/9 mm
ISBN
9789819727223
Entdecken Sie mehr
Bewertungen
0 Bewertungen
Es wurden noch keine Bewertungen abgegeben. Schreiben Sie die erste Bewertung zu "Cracking the Machine Learning Code: Technicality or Innovation?" und helfen Sie damit anderen bei der Kaufentscheidung.